To follow up from RSS reader: Alternette, and get a sense of where Alternette is. To start like a good Apple Keynotes, numbers:
- 100,869 new entries added
- 5,299 opened entries!!
Infrastructure
I’m hosting the service on vercel and was using a neon.tech database. I was seeing some timeout issues and neon.tech was rolling out their free plan. I wasn’t sure how much it would cost so I decided to switch to crunchy data with their $10/month plan. I’m using their Crunchy Bridge and they have a nice cb CLI. Then I got an index issue where I was looking up the URL of an entry to check if it was already added from another source, it was painful.
I’ve migrated away from pinecone and use pgvector directly. Pinecone sent a scary email saying they accidentaly removed indexes (which they do if an index is inactive after 7 days). Since I wanted to explore pgvector it was a good time to do. Dealing with the postgres side was simply: CREATE EXTENSION IF NOT EXISTS vector WITH schema public;, but then prisma doesn’t support vector type, and doesn’t support fields with custom type, so every operation you do, has to be in raw SQL. There are GitHub issues talking about it, I won’t be surprised if they support it soon.
Features
I’ve added 2 main features:
- being able to see which sources I’m not reading to remove them if they don’t align with my preferences anymore
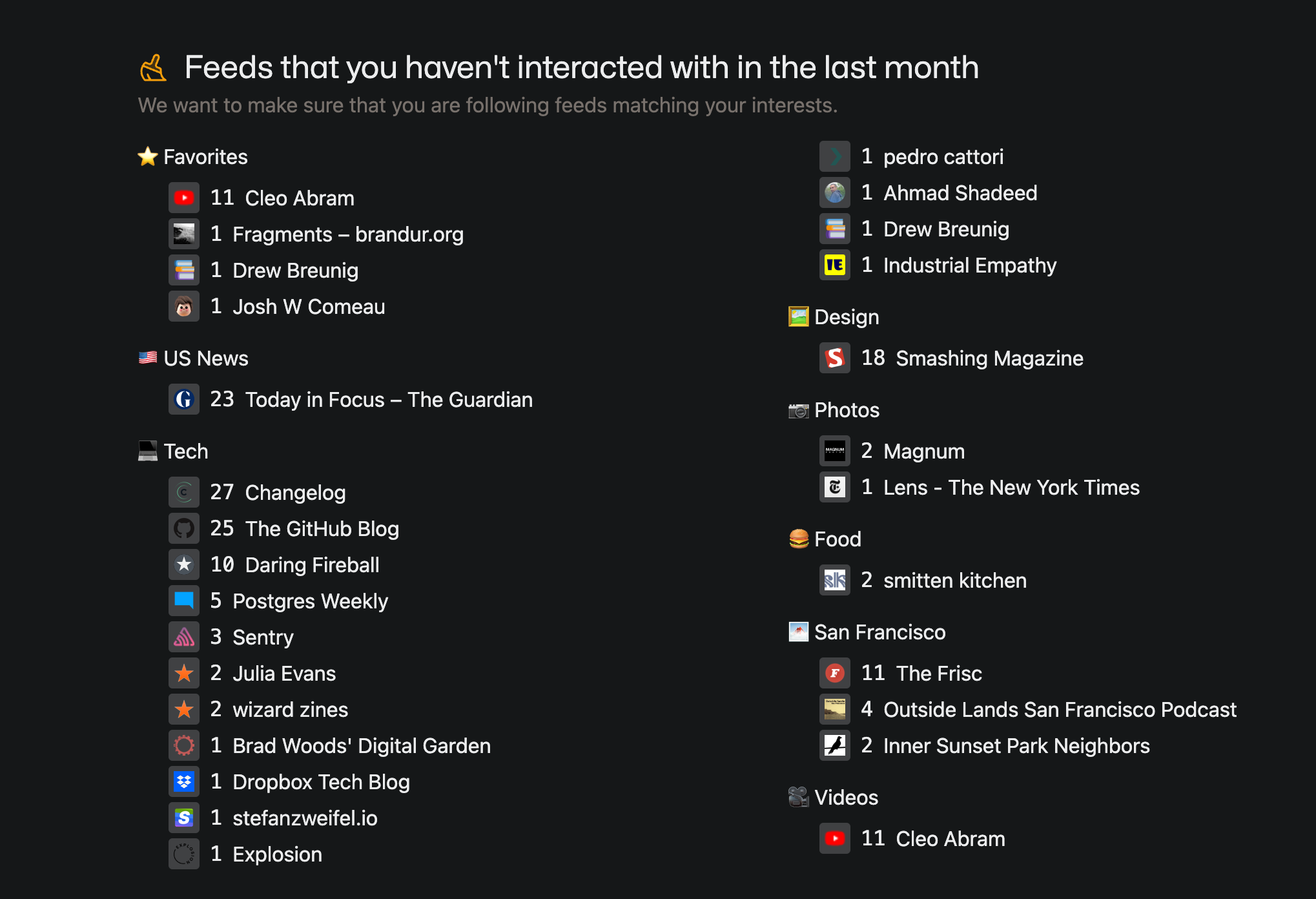
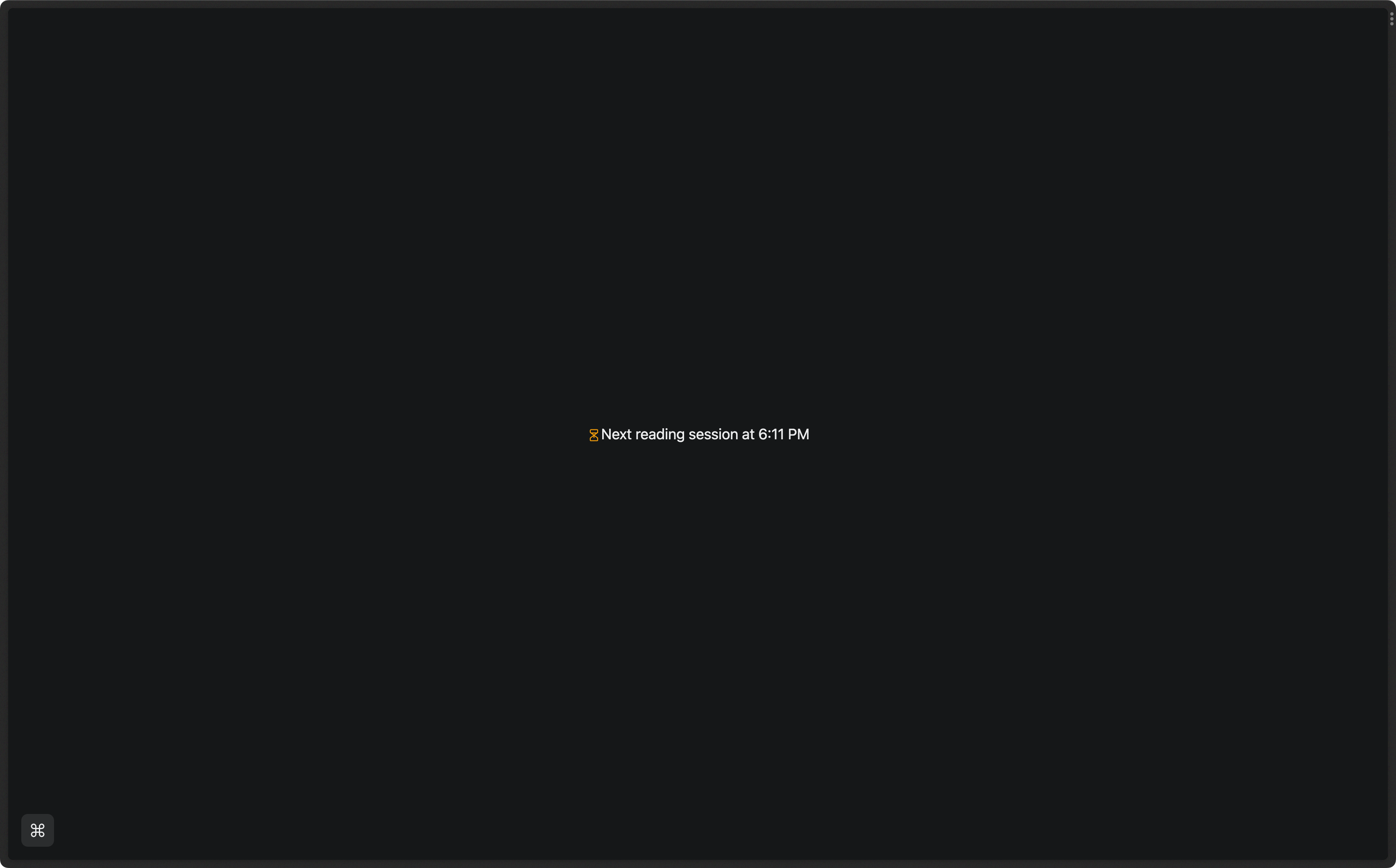
- a lock to only be able to read content every 2 hours! and this is huge. It would come time when procrastination would take over and I would check the app every 10 minutes.
What is next?
- search, now that I have the embeddings in the database, I need to add the flow to:
- get embeddings for the search query
- query database to fetch the closest results
- find a UI
- better onboarding with bucket and source management. I don’t focus on how other people would use the tool but it would be a good UX exercise.